


أعلنت شركة المتصفحات الإلكترونية أوبرا اليوم عن فتح إمكانية لمستخدميها لتنزيل واستخدام نماذج اللغة الكبيرة (LLMs) محلياً على أجهزتهم الشخصية. هذه الميزة ستكون متاحة أولاً لمستخدمي أوبرا الذين يتلقون تحديثات بث المطورين وستتيح لهم اختيار أكثر من 150 نموذجًا من أكثر من 50 عائلة.
تشمل هذه النماذج Llama من Meta، وGemma من Google، وVicuna. ستكون هذه الميزة جزءًا من برنامج Opera’s AI Feature Drops للسماح للمستخدمين بالوصول المبكر إلى بعض ميزات الذكاء الاصطناعي.
وأكدت الشركة أنها تستخدم إطار عمل Ollama مفتوح المصدر في المتصفح لتشغيل هذه النماذج على أجهزة المستخدمين. وعلى الرغم من أن جميع النماذج المتاحة حالياً تعتمد على مكتبة Ollama، إلا أن الشركة تعتزم في المستقبل توفير نماذج من مصادر متنوعة.
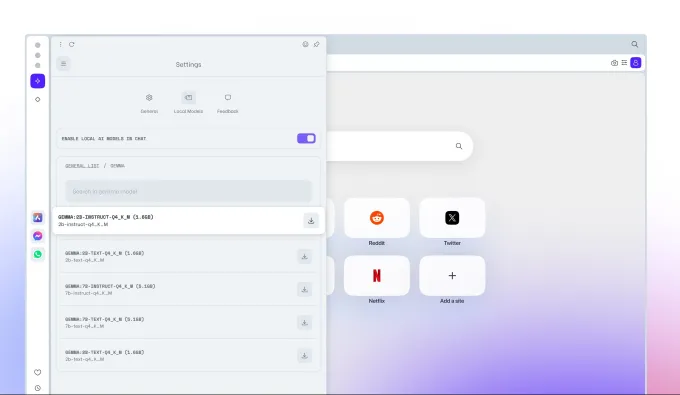
وأشارت الشركة إلى أن كل نموذج سيستهلك أكثر من 2 جيجابايت من مساحة التخزين المحلية لدى المستخدم. لذا يجب على المستخدمين مراعاة المساحة المتاحة لديهم لتفادي نفاد المساحة. ولاحظت الشركة أنها لا تعمل على تقليل حجم التخزين أثناء تنزيل النموذج.
وقال جان ستاندال، نائب الرئيس في أوبرا، في تصريح لموقع TechCrunch: “تمثل هذه الميزة أول وصول لأوبرا إلى مجموعة كبيرة من LLMs المحلية من أطراف ثالثة مباشرة في المتصفح. ومن المتوقع أن ينخفض حجم هذه النماذج مع تخصصها المتزايد للمهام المحددة”.
وتعتبر هذه الميزة مفيدة للمستخدمين الذين يرغبون في اختبار نماذج مختلفة على أجهزتهم المحلية. ولكن إذا كنت تبحث عن توفير المساحة، فهناك العديد من الأدوات المتاحة عبر الإنترنت مثل Poe من Quora وHuggingChat لاستكشاف نماذج مختلفة.
وقد بدأت أوبرا في استكشاف ميزات تعتمد على الذكاء الاصطناعي منذ العام الماضي. وقد أطلقت الشركة مساعداً يسمى Aria في الشريط الجانبي في مايو الماضي، وقدمته لنسخة iOS في أغسطس. وفي يناير، أعلنت أوبرا أنها تقوم ببناء متصفح يعتمد على الذكاء الاصطناعي بمحركها الخاص لنظام iOS بناءً على طلب Digital Market Acts (DMA) في الاتحاد الأوروبي.
 محلياً على أجهزتهم الشخصية){kind=link}